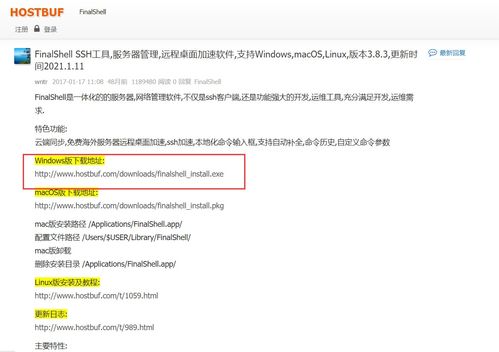
崔庆才是一位知名的技术博主,他在个人博客上分享了大量关于前端开发、Python爬虫、数据分析等技术内容。对于学习前端开发或希望了解其网站构建方式的开发者来说,抓取他的个人博客前端源码是一次很好的实践机会。
一、抓取前端源码的意义
抓取网站前端源码可以帮助我们:
- 学习优秀的代码结构:崔庆才的博客前端设计简洁、响应式布局合理,适合初学者分析学习。
- 理解前端技术栈:通过源码可以了解HTML、CSS、JavaScript等技术的实际应用,尤其是现代框架(如Vue、React)的运用。
- 获取设计灵感:博客的样式和交互设计可以为个人项目提供参考。
二、如何抓取前端源码
抓取前端源码有多种方法,这里介绍几种常用方式:
- 使用浏览器开发者工具:
- 打开崔庆才的博客网站(如https://cuiqingcai.com)。
- 右键点击页面,选择“查看页面源代码”或按F12打开开发者工具。
- 在“Elements”标签中查看HTML结构,在“Sources”标签中下载CSS和JS文件。
- 使用爬虫工具:
- 编写Python脚本,使用Requests库获取HTML内容,再用BeautifulSoup解析。
- 对于动态加载的内容,可以使用Selenium模拟浏览器行为。
- 在线工具:一些网站提供整站下载功能,但需注意版权和伦理问题。
三、注意事项
在抓取过程中,请务必遵守以下原则:
- 尊重版权:崔庆才的博客内容受版权保护,抓取源码仅用于个人学习,不可用于商业用途或重新发布。
- 遵守robots.txt:检查网站根目录下的robots.txt文件,确保抓取行为不被禁止。
- 避免过度请求:设置合理的请求间隔,防止对服务器造成压力。
四、源码分析示例
假设我们抓取了崔庆才博客的首页HTML,可以发现:
- 使用语义化标签(如
、 )提升可读性和SEO。 - CSS采用Flexbox或Grid布局实现响应式设计。
- JavaScript可能用于交互功能,如评论加载或文章搜索。
五、总结
抓取崔庆才个人博客前端源码是一次宝贵的学习经历,不仅能提升技术能力,还能加深对前端开发流程的理解。但请始终牢记伦理和法律边界,将所学用于正途。通过分析和模仿优秀代码,你可以逐步构建出自己的高质量博客或项目。